| Contents | Transport layer | Packet format | Application Protocol | Let's write a server |
Packet format
e-Amusement uses XML for its application layer payloads. This XML is either verbatim, or in a custom packed binary format.
The XML format
Each tag that contains a value has a __type attribute that identifies what type it is. Array types
have a __count attribute indicating how many items are in the array. Binary blobs additionally have
a __size attribute indicating their length (this is notably not present on strings, however).
It is perhaps simpler to illustrate with an example, so:
<?xml version='1.0' encoding='UTF-8'?> <call model="KFC:J:A:A:2019020600" srcid="1000" tag="b0312077"> <eventlog method="write"> <retrycnt __type="u32" /> <data> <eventid __type="str">G_CARDED</eventid> <eventorder __type="s32">5</eventorder> <pcbtime __type="u64">1639669516779</pcbtime> <gamesession __type="s64">1</gamesession> <strdata1 __type="str" /> <strdata2 __type="str" /> <numdata1 __type="s64">1</numdata1> <numdata2 __type="s64" /> <locationid __type="str">ea</locationid> </data> </eventlog> </call>
Arrays are encoded by concatenating every value together, with spaces between them. Data types that have multiple values, are serialized similarly.
Therefore, an element storing an array of 3u8 ([(1, 2, 3), (4, 5, 6)]) would look like
this
<demo __type="3u8" __count="2">1 2 3 4 5 6</demo>
Besides this, this is otherwise a rather standard XML.
Packed binary overview
Many packets, rather than using a string-based XML format, use a custom binary packed format instead. While it can be a little confusing, remembering that this is encoding an XML tree can make it easier to parse.
To start with, let's take a look at the overall structure of the packets.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| A0 | C | E | ~E | Head length | |||||||||||
| Schema definition | |||||||||||||||
| FF | Align | ||||||||||||||
| Data length | |||||||||||||||
| Payload | |||||||||||||||
| Align | |||||||||||||||
Every packet starts with the magic byte 0xA0. Following this is the content byte, the encoding byte,
and then the 2's compliment of the encoding byte.
Possible values for the content byte are:
| C | Content |
0x42 |
Packed names, contains data |
0x43 |
Packed names, schema only |
0x45 |
Full names, contains data |
0x46 |
Full names, schema only |
Source code details
Not totally cleaned these up yet, but the general concept of how packets are parsed can be seen fairly clearly.
At a high level, we have a single function that validates the header, parses out the schema, then goes to read
the body of the packet, if we're expecting it. The arguments to parse_packet_header will make more
sense in a moment.
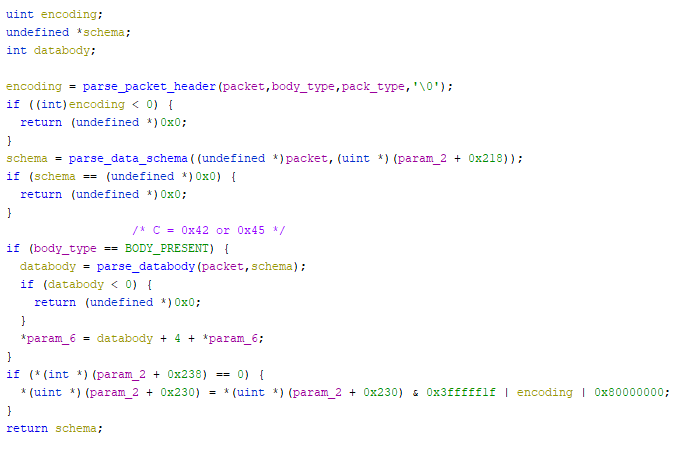
libavs-win32.dll:0x1003483parse_packet_header has a lot of things going on, so I'm just pulling out a few important snippets
here.



libavs-win32.dll:0x1003448cWe first read out four bytes from the start of the packet, and convert that to an integer; nothing especially
magic here. The next block however is potentially not the first that you might have expected to see. Based on
the two flags passed into the function arguments, we are going to subtract a value from this header.
Specifically, the first byte we subtract is always 0xa0, then the second byte are those
C value in the table above.
Finally, we mask out the first two bytes, and assert that they're both null. That is, they are exactly equal to the value we subtracted from them. Of note here is that the caller to this function "decides" what sort of packet it is expecting.
We can also see the check for ~E here. If that check passes, we return the E byte,
otherwise we're going to error.
The encoding flag indicates the encoding for all string types in the packet (more on those later). Possible values are:
E |
~E |
Encoding name | ||
0x00 |
0xFF |
None | ||
0x20 |
0xDF |
ASCII |
||
0x40 |
0xBF |
ISO-8859-1 |
ISO_8859-1 |
|
0x60 |
0x9F |
EUC-JP |
EUCJP |
EUC_JP |
0x80 |
0x7F |
SHIFT-JIS |
SHIFT_JIS |
SJIS |
0xA0 |
0x5F |
UTF-8 |
UTF8 |
|
Data is assumed by default to be in ISO 8859 encoding. That is, for encodings 0x00 and
0x40, no transformation is performed on the binary data to produce readable text.
ASCII encoding is true 7-bit ASCII, with the 8th bit always set to 0. This is validated.
Source code details
The full table for these values can be found in libavs.

libavs-win32.dll:0x1006b960A second table exists just before this on in the source, responsible for the
<?xml version='1.0' encoding='??'?> line in XML files.
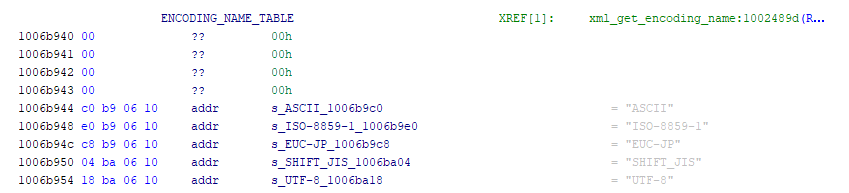
libavs-win32.dll:0x1006b940This is indexed using the following function, which maps the above encoding IDs to 1, 2, 3, 4 and 5 respectively.
char* xml_get_encoding_name(uint encoding_id) { return ENCODING_NAME_TABLE[((encoding_id & 0xe0) >> 5) * 4]; }
While validating ~E isn't technically required, it acts as a useful assertion that the packet being
parsed is valid.
The packet schema header
Following the 4 byte header, is a 4 byte integer containing the length of the next part of the header (this is technically made redundant as this structure is also terminated).
This part of the header defines the schema that the main payload uses.
A tag definition follows one of the following three formats:
-
Compressed names:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Type nlen Tag name Attributes and children FE -
Full names, short length:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Type 0x40-0x64 Tag name Attributes and children FE -
Full names, long length:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Type 0x80-0x8f 0x00-0xff Tag name Attributes and children FE
The encoding of structure names varies depending on the packet content byte. If the content flag indicated we have a
full string, we first need to check if the value of the first byte exceeds 0x7f. If it does, we need to
read an additional byte. In the single byte case, we subtract 0x3f1 to get our real length.
In the two byte case we subtract 0x7fbf2. In the latter case, the maximum allowed length is
0x1000.
1 simplified from (length & ~0x40) + 0x01
2 simplified from (length & ~0x8000) + 0x41
If we are instead parsing packed names, then the names are encoded as densely packed 6 bit values. The length prefix
(nlen) determines the length of the final unpacked string. The acceptable alphabet is
0123456789:ABCDEFGHIJKLMNOPQRSTUVWXYZ_abcdefghijklmnopqrstuvwxyz, and the packed values are indecies
within this alphabet. The maximum length for a name in this mode is 36 bytes (0x24).
The children can be a combination of either attribute names, or child tags. Attribute names are represented by
the byte 0x2E followed by a length prefixed name as defined above. Child tags follow the above
format. Type 0x2E must therefore be considered reserved as a possible structure type. As they carry
special meaning in text-bsaed XML encoding, attribute names beginning with __ are disallowed.
Source code details
I'm not going to labour this one, so if you want to go look yourself:
- 6-packed name reader:
libavs-win32.dll:0x10009f90 - Unpacked name reader:
libavs-win32.dll:0x1000a110 - The call to the above:
libavs-win32.dll:0x10034a57, with the__checking starting atlibavs-win32:0x10034cfdfor attributes (i.e. theJZat0x10034a7c)
Attributes (type 0x2E) represent a string attribute. Any other attribute must be defined as a child
tag. Is it notable that 0 children is allowable, which is how the majority of values are encoded.
All valid IDs, and their respective type, are listed in the following table. The bucket column here will be used later when unpacking the main data, so we need not worry about it for now, but be warned it exists and is possibly the least fun part of this format.
| ID | Bytes | C type | Bucket | XML names | ID | Bytes | C type | Bucket | XML names | |||
| 0x01 | 0 | void | - | void | 0x21 | 24 | uint64[3] | int | 3u64 | |||
| 0x02 | 1 | int8 | byte | s8 | 0x22 | 12 | float[3] | int | 3f | |||
| 0x03 | 1 | uint8 | byte | u8 | 0x23 | 24 | double[3] | int | 3d | |||
| 0x04 | 2 | int16 | short | s16 | 0x24 | 4 | int8[4] | int | 4s8 | |||
| 0x05 | 2 | uint16 | short | u16 | 0x25 | 4 | uint8[4] | int | 4u8 | |||
| 0x06 | 4 | int32 | int | s32 | 0x26 | 8 | int16[4] | int | 4s16 | |||
| 0x07 | 4 | uint32 | int | u32 | 0x27 | 8 | uint8[4] | int | 4u16 | |||
| 0x08 | 8 | int64 | int | s64 | 0x28 | 16 | int32[4] | int | 4s32 | vs32 | ||
| 0x09 | 8 | uint64 | int | u64 | 0x29 | 16 | uint32[4] | int | 4u32 | vs32 | ||
| 0x0a | prefix | char[] | int | bin | binary | 0x2a | 32 | int64[4] | int | 4s64 | ||
| 0x0b | prefix | char[] | int | str | string | 0x2b | 32 | uint64[4] | int | 4u64 | ||
| 0x0c | 4 | uint8[4] | int | ip4 | 0x2c | 16 | float[4] | int | 4f | vf | ||
| 0x0d | 4 | uint32 | int | time | 0x2d | 32 | double[4] | int | 4d | |||
| 0x0e | 4 | float | int | float | f | 0x2e | prefix | char[] | int | attr | ||
| 0x0f | 8 | double | int | double | d | 0x2f | 0 | - | array | |||
| 0x10 | 2 | int8[2] | short | 2s8 | 0x30 | 16 | int8[16] | int | vs8 | |||
| 0x11 | 2 | uint8[2] | short | 2u8 | 0x31 | 16 | uint8[16] | int | vu8 | |||
| 0x12 | 4 | int16[2] | int | 2s16 | 0x32 | 16 | int8[8] | int | vs16 | |||
| 0x13 | 4 | uint16[2] | int | 2u16 | 0x33 | 16 | uint8[8] | int | vu16 | |||
| 0x14 | 8 | int32[2] | int | 2s32 | 0x34 | 1 | bool | byte | bool | b | ||
| 0x15 | 8 | uint32[2] | int | 2u32 | 0x35 | 2 | bool[2] | short | 2b | |||
| 0x16 | 16 | int16[2] | int | 2s64 | vs64 | 0x36 | 3 | bool[3] | int | 3b | ||
| 0x17 | 16 | uint16[2] | int | 2u64 | vu64 | 0x37 | 4 | bool[4] | int | 4b | ||
| 0x18 | 8 | float[2] | int | 2f | 0x38 | 16 | bool[16] | int | vb | |||
| 0x19 | 16 | double[2] | int | 2d | vd | 0x38 | ||||||
| 0x1a | 3 | int8[3] | int | 3s8 | 0x39 | |||||||
| 0x1b | 3 | uint8[3] | int | 3u8 | 0x3a | |||||||
| 0x1c | 6 | int16[3] | int | 3s16 | 0x3b | |||||||
| 0x1d | 6 | uint16[3] | int | 3u16 | 0x3c | |||||||
| 0x1e | 12 | int32[3] | int | 3s32 | 0x3d | |||||||
| 0x1f | 12 | uint32[3] | int | 3u32 | 0x3e | |||||||
| 0x20 | 24 | int64[3] | int | 3s64 | 0x3f | |||||||
Strings should be encoded and decoded according to the encoding specified in the packet header. Null termination is optional, however should be stripped during decoding.
All of these IDs are & 0x3F. Any value can be turned into an array by setting the 7th bit
high (| 0x40). Arrays of this form, in the data section, will be an aligned size: u32
immediately followed by size bytes' worth of (unaligned!) values of the unmasked type. Despite being a
u32, the maximum length allowed is 0xffffff.
Source code details
The full table for these values can be found in libavs. This table contains the names of every tag, along with additional information such as how many bytes that data type requires, and which parsing function should be used.

libavs-win32.dll:0x100782a8Note about the array type:
While I'm not totally sure, I have a suspicion this type is used internally as a pseudo-type. Trying to identify its function as a parsable type has some obvious blockers:
All of the types have convenient printf-using helper functions that are used to emit them when
serializing XML. All except one.
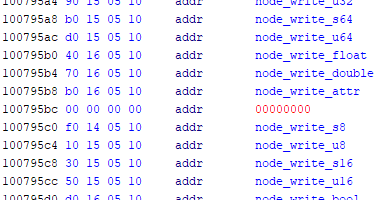
If we have a look inside the function that populates node sizes (libavs-win32.dll:0x1000cf00),
it has an explicit case, however is the same fallback as the default case.
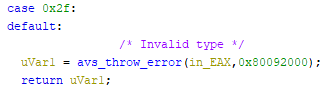
In the same function, however, we can find a second (technically first) check for the array type.

This seems to suggest that internally arrays are represented as a normal node, with the array
type, however when serializing it's converted into the array types we're used to (well, will be after the
next sections) by masking 0x40 onto the contained type.
Also of interest from this snippet is the fact that void, bin, str,
and attr cannot be arrays. void and attr make sense, however
str and bin are more interesting. I suspect this is because konami want to be able
to preallocate the memory, which wouldn't be possible with these variable length structures.
The data section
This is where all the actual packet data is. For the most part, parsing this is the easy part. We traverse our schema, and read values out of the packet according to the value indicated in the schema. Unfortunately, konami decided all data should be aligned very specifically, and that gaps left during alignment should be backfilled later. This makes both reading and writing somewhat more complicated, however the system can be fairly easily understood.
Firstly, we divide the payload up into 4 byte chunks. Each chunk can be allocated to either store individual bytes, shorts, or ints (these are the buckets in the table above). When reading or writing a value, we first check if a chunk allocated to the desired type's bucket is available and has free/as-yet-unread space within it. If so, we will store/read our data to/from there. If there is no such chunk, we claim the next unclaimed chunk for our bucket.
For example, imagine we write the sequence byte, int, byte, short, byte, int, short. The final output
should look like:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| byte | byte | byte | int | short | short | int | |||||||||
While this might seem a silly system compared to just not aligning values, it is at least possible to intuit that it
helps reduce wasted space. It should be noted that any variable-length structure, such as a string or an array,
claims all chunks it encroaches on for the int bucket, disallowing the storage of bytes or shorts
within them.
Implementing a packer
While the intuitive way to understand the packing algorithm is via chunks and buckets, a far more efficient implementation can be made that uses three pointers. Rather than try to explain in words, hopefully this python implementation should suffice as explanation:
class Packer: def __init__(self, offset=0): self._word_cursor = offset self._short_cursor = offset self._byte_cursor = offset self._boundary = offset % 4 def _next_block(self): self._word_cursor += 4 return self._word_cursor - 4 def request_allocation(self, size): if size == 0: return self._word_cursor elif size == 1: if self._byte_cursor % 4 == self._boundary: self._byte_cursor = self._next_block() + 1 else: self._byte_cursor += 1 return self._byte_cursor - 1 elif size == 2: if self._short_cursor % 4 == self._boundary: self._short_cursor = self._next_block() + 2 else: self._short_cursor += 2 return self._short_cursor - 2 else: old_cursor = self._word_cursor for _ in range(math.ceil(size / 4)): self._word_cursor += 4 return old_cursor def notify_skipped(self, no_bytes): for _ in range(math.ceil(no_bytes / 4)): self.request_allocation(4)